从零开始爬取疫情并云端数据可视化
实验OS环境:Win10 /ubuntu 16.04
安装python
首先需要安装Python, windows版本在Python网站下载 msi安装版 (py3.71)
Win64版本下载网址
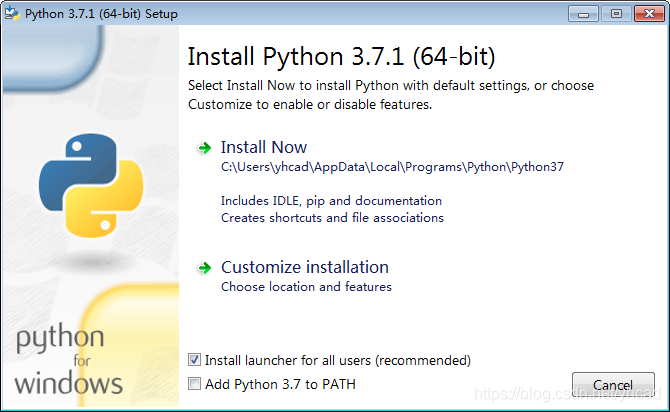
自动添加环境变量勾选下方“Add Python 3.7 to PATH”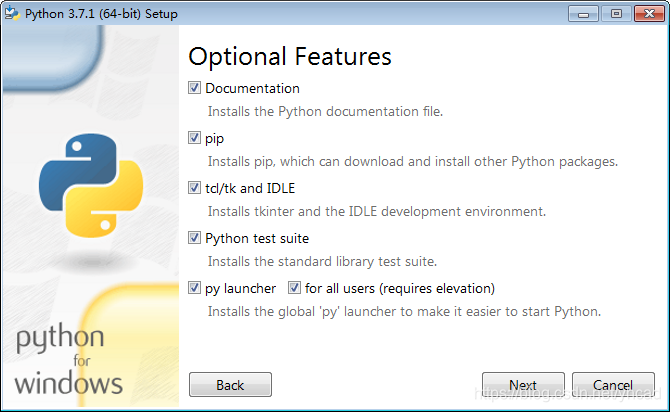
手动设置环境变量:在系统环境变量中添加安装路径 (省略号表示安装路径的前缀)
….\Python37\Scripts\;….\Python37\
step1:测试安装
输入python 回车出现下述shell场景表示安装成功, 输入exit()退出

安装Streamlit
streamlit 是第一个专门针对机器学习和数据科学团队的应用开发框架,它是开发自定义机器学习工具的最快的方法,可以调用tornado与其他可视化包的网站框架。官网地址
本文使用streamlit的地图可视化官方教程Github
step2: 测试安装成果
cmd 输入 pip install streamlit, 安装完成后输入streamlit hello 测试是否安装成功,浏览器中进入 http://localhost:8501 出现下述场景表示安装完成, cmd中按住ctrl+c可以退出

cmd 输入 pip install json, 完成安装json解析库
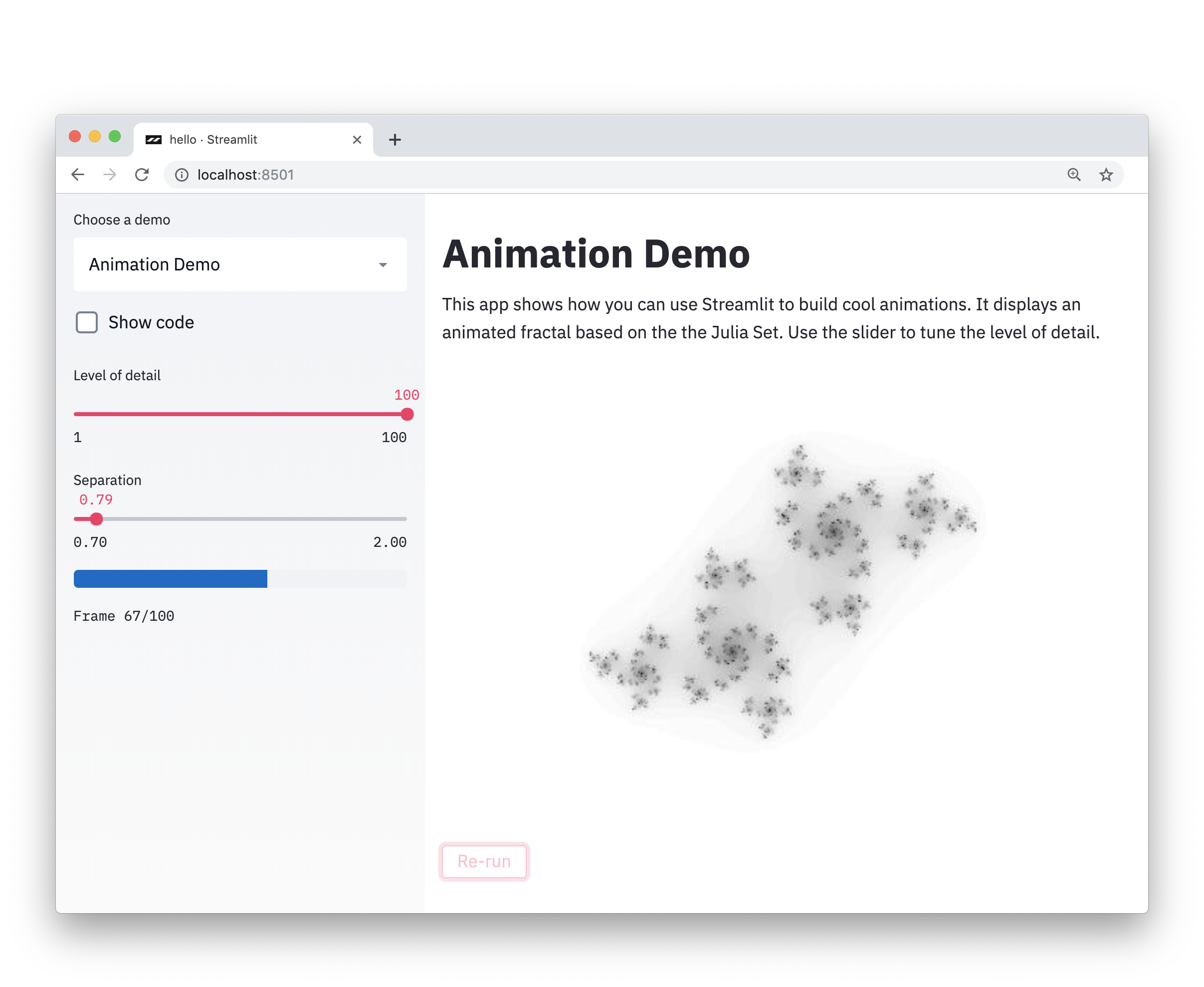
在丁香园网上爬取数据
step3:创建web_get.py文件
需要导入的依赖库有
1 | import streamlit as st |
step4:使用爬虫爬取丁香园数据
- 首先在浏览器进入丁香园网址 按下F12查看网页信息,找到数据项藏在
<strip id = "window.getAreaStat"></strip>中

写一个正则表达式,将中间的数据提取出来
want = re.compile(r' window.getAreaStat.*?</script>', re.S)对html进行匹配得到数据,并转化为string格式
result = want.findall(str(html.decode("utf-8")))此时的结果是字符串格式的
需要对数据处理,将不必要的符号和其他的无意义单词去除
将字符串转化为json格式:
json.loads(result)
1 |
|
地图可视化
step5:转化数据格式,
分析json格式的输出,里面的格式是字典类型的映射,获得省份的数据使用data['provinceName']获得各个城市的确诊人数data['provinceName']['cities']['confirmedCount'], 此时只有当前省份和城市的数据,要在地图上是可视化需要得到各个城市的地理坐标(经纬度信息)
在pyecharts中查询地理坐标需要导入中国城市的地图包,本文使用一个带有全国地理信息的json文件作为原始信息,并对该文件解析,得到各个城市的地理位置信息。该json文件来源于网络,需要对一些不规则的结构略作处理,并对地名找不到的异常处理。
1 | def get_lat_by_name(name: str, pos_dic): |
转化为需要的格式[cityName, counts, latitude, longitude]
1 | def get_cities_data(json_output, pos_dic): |
最后将数据转化Pandas包的DataFrame 格式
data = get_cities_data(get_data_from_web(), get_pos_by_json())
data = pd.DataFrame(data, columns=['lat', 'lon', 'cityName', 'counts'])
step6: 可视化
streamlit 使用的数据可视化包是Uber团队开发的开源地图deck.gl 在安装streamlit的同时已经附带安装了deckgl的python封装库pydeck。
此时直接将数据输入pydeck的接口中不能完全显示,需要先定义一个摄像机观察位置
view_point= [32.33, 113.32]
1 | # initial view state : |
在当前的python文件路径下使用cmd输入
streamlit run you_file_name.py
step7: 浏览器打开网址loacalhost:8501

1 | cmd下输入 ctrl+c 可以退出 |